The Ultimate Hack for Supercharging Your CircleCI Pipeline!
In this blog, we will be taking a closer look at optimizing pytest-based CircleCI pipelines.

🚀 Prerequisites
An existing CircleCI pipeline.
Basic knowledge of Pytest.
Basic knowledge of YAML files.
🌅 Background
We have a couple thousand test cases as the test suite of the Django app powering Certa. To ensure CI, we are utilizing CircleCI to validate the PRs before merging them onto the repository's development branch.
😬 The problem
Due to the reasons listed below, developers were being slowed down and had to monitor and re-run test cases when merging their PR constantly.
The total duration of the test run before optimization was ~28 min.
Due to the size & history of the test suite, flaky test cases used to be a frequent occurrence.
🤔 Solutions
📊 Distributing test cases based on timing
By default, test cases are distributed among containers based on the file names, which can lead to skewed timings like this:
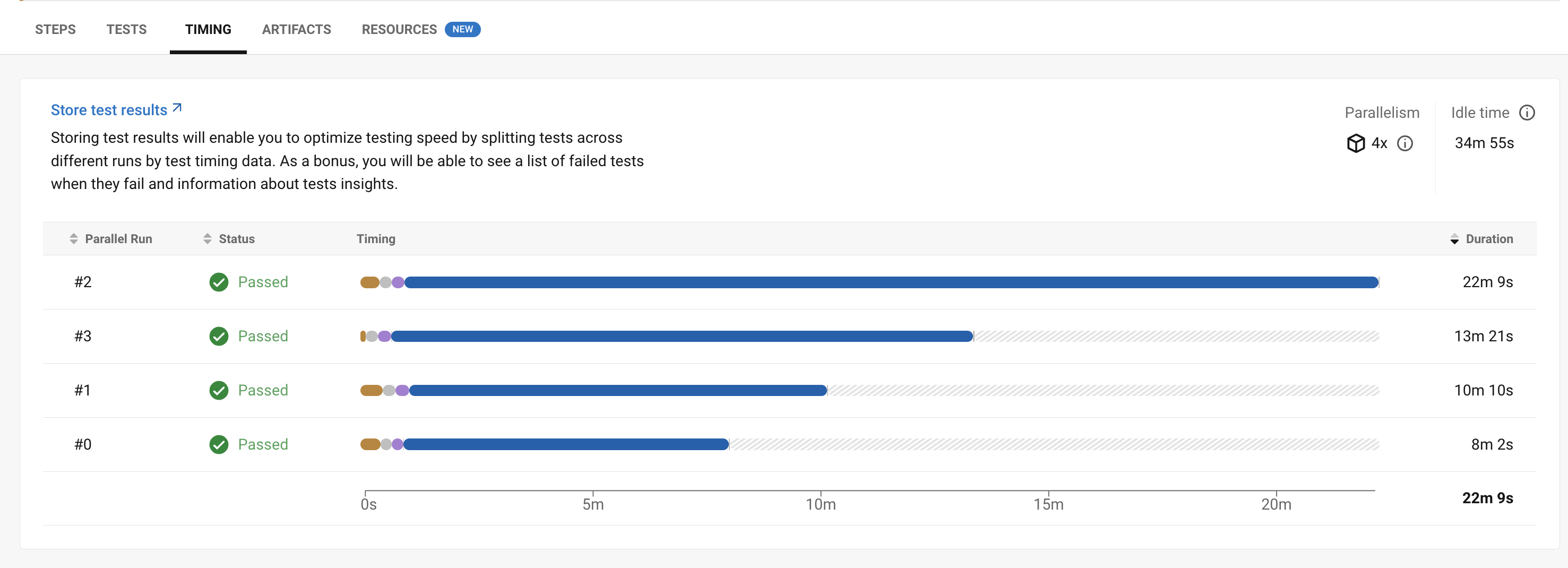
Splitting based on timings would shave out much of the test duration for no extra cost.
Steps:
Upload test run report
After a test run to get the test cases to generate a report once their run is completed
- run: # this will create the dir to store the reports name: Make test report dir command: mkdir -p test-results/reports - run: # we split the test cases using timing and generates report at the end of test run name: Run tests and create report command: | TESTFILES="$(circleci tests glob "<test dir path>/**/test_*.py" | circleci tests split --split-by=timings) pytest ${TESTFILES} --junitxml=test-results/reports/junit.xml - store_test_results: # this will ensure test results are stored in CircleCI for timing data for later runs. path: test-resultsNote: By default, the reports we generate use
xunit2format to store test results that do not contain the file paths and hence can't be used to generate timing data at the time of writing this blog. A workaround we used is to specify the following in thesetup.cfgthe file of the Django project:[tool:pytest] python_files = test*.py junit_family = xunit1Split test cases based on timings
Once we have the timing data available on CircleCI, then we can add split-by-timing to the YAML file as follows(re-iterating):
- run: # we split the test cases using glob and generates report at the end of test run name: Run tests and create report command: | TESTFILES="$(circleci tests glob "<test dir path>/**/test_*.py" | circleci tests split --split-by=timings) pytest ${TESTFILES} -n 4 --reuse-db --junitxml=test-results/reports/junit.xmlThe
runcommand uses two things, the first is to get all the test files using glob and then to initiate the test run by specifying to use timing as the split criteria.Set timing-type
Now that we have timing data, we can set the granularity. CircleCI supports 4 different choices:
filename,classname,testnameandautodetect. This choice will depend on your needs butclassnameworked best for our case.
Cost vs Impact
- No additional cost was associated with this change, but it significantly improved the timings, reducing the overall duration by 36%.
Caveats
- The
store_test_resultscommand needs a directory as input. The test results need to be stored inside this directory.
- The
📈 Increasing container count
This is an obvious option available to you, but the problem is that it will incur higher credit usage. This particular option varies based on projects, we found that 8 containers of the large class are the ideal configuration for our use case, which saves time while not burning away credits. Below are the YAML file changes:
working_directory: ~/repo resource_class: large parallelism: 8 steps: - attach_workspace: at: ~/repo - run: # we split the test cases using glob and generate the report at the end of the test run name: Run tests and create report command: | TESTFILES="$(circleci tests glob "<test dir path>/**/test_*.py" | circleci tests split --split-by=timings) pytest ${TESTFILES} -n 4 --reuse-db --junitxml=test-results/reports/junit.xmlCost vs Impact
- The Addon cost was around 100k credits per month. It reduced the timings by around 28% and also consumed a lot of time to find the sweet spot since each time after changing the number, we had to run the pipeline completely to get the impact.
Caveats
This will be time-consuming; what we have done to make it easier is to push several commits with only the job container count changed and run the pipelines in parallel manually. By default, it cancels a job when a new commit is pushed, so you must manually rerun the suite.
Increasing parallelism can also lead to an increase in flaky test cases, depending on your test suite. There can be multiple reasons for this - race conditions, resource contention, or synchronization issues. Read on to learn about the solutions that worked for us.
🏎️ Parallel test runs with a job
If you already have parallel containers running the jobs, then one thing to keep track of is the resource usage section of the test run. Below is the screenshot of an unoptimized job.
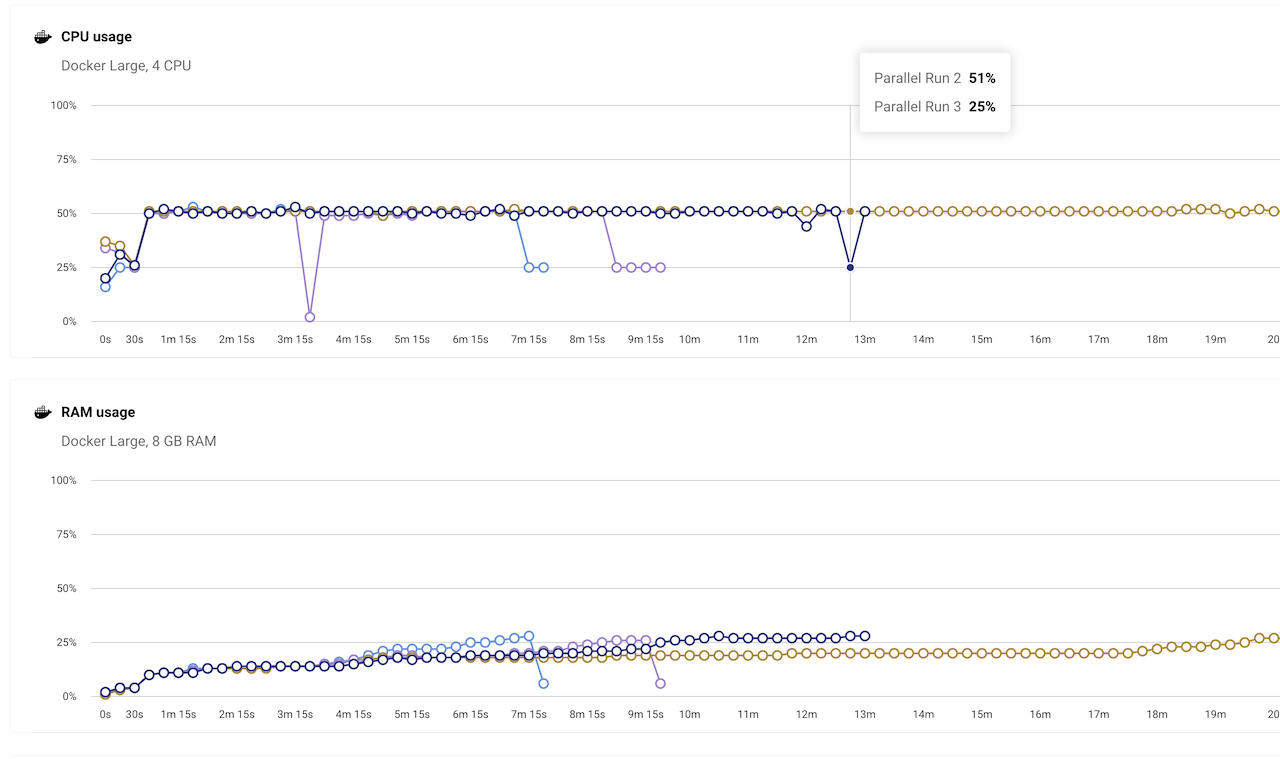
As the screenshot shows, jobs were utilizing at most 50% of the CPU. An easy remedy we applied is to utilize the number of parallel pytest instances running in a container. Below is the config change for increasing the instances to 4:
working_directory: ~/repo resource_class: large parallelism: 8 steps: - attach_workspace: at: ~/repo - run: # we split the test cases using glob and generate the report at the end of the test run name: Run tests and create report command: | TESTFILES="$(circleci tests glob "<test dir path>/**/test_*.py" | circleci tests split --split-by=timings) pytest ${TESTFILES} -n 4 --reuse-db --junitxml=test-results/reports/junit.xmlNote: Low CPU resource usage is expected if your test suite is IO-heavy. In such cases lowering the resource type can yield some savings on credits.
Cost vs Impact
- No additional cost was associated with this change, and the impact was not great either. On average, it saved about 1-2 mins (3.8%) per test run.
Caveats
- When you optimize this value, if you don't see at least a 15% improvement compared to the previous value, then it is time to stop since, post that, your cost increase will probably be unjustifiable.
💾 Using cache and workspace storage
Projects that utilize external libraries or files that remain relatively constant between multiple test runs can be cached and used to save a significant amount of time. We used:
cache to store our python libraries by generating a key based on the hash of the requirement files
workspaces cache to create a common test env from which different test jobs start.
The config is as follows:
prep-test-env: parameters: resource_class: type: string description: CircleCI resource class default: medium docker: - image: cimg/python:3.9.16 working_directory: ~/repo resource_class: large steps: - checkout - run: # Generate a hash based on requirements name: Check if requirements changed command: | echo $(find ./requirements -type f -exec md5sum {} \; | md5sum | cut -d' ' -f1) >> REQUIREMENTS_CACHE_KEY - restore_cache: keys: - dependencies-{{ checksum "REQUIREMENTS_CACHE_KEY" }} - run: # this will install any new dependency added name: Install python dependencies command: | python -m venv venv . venv/bin/activate pip install --upgrade setuptools pip install -e . for file in requirements/*.txt; do pip install -r "$file"; done - save_cache: paths: - venv key: dependencies-{{ checksum "REQUIREMENTS_CACHE_KEY" }} - persist_to_workspace: root: ~/repo paths: ./In our job for the test run, we will attach this saved workspace as follows:
steps: - attach_workspace: at: ~/repoTo specify the order in which we define the following in the workflows section
workflows: version: 2 app-tests: jobs: - prep-test-env: name: Prepare the test environment - run-test: name: Test run requires: - Prepare the test environmentThis will ensure the
prep-test-envruns before the test cases are run.Cost vs Impact
- This caused an additional cost of ~3k credits per month, including caches and workspace storage. This saved about 40 seconds from each test run job, which is significant since each parallel job consumes credits independently.
Caveats
Do make sure to set the usage policy to avoid storing irrelevant data. We have set it as follows:
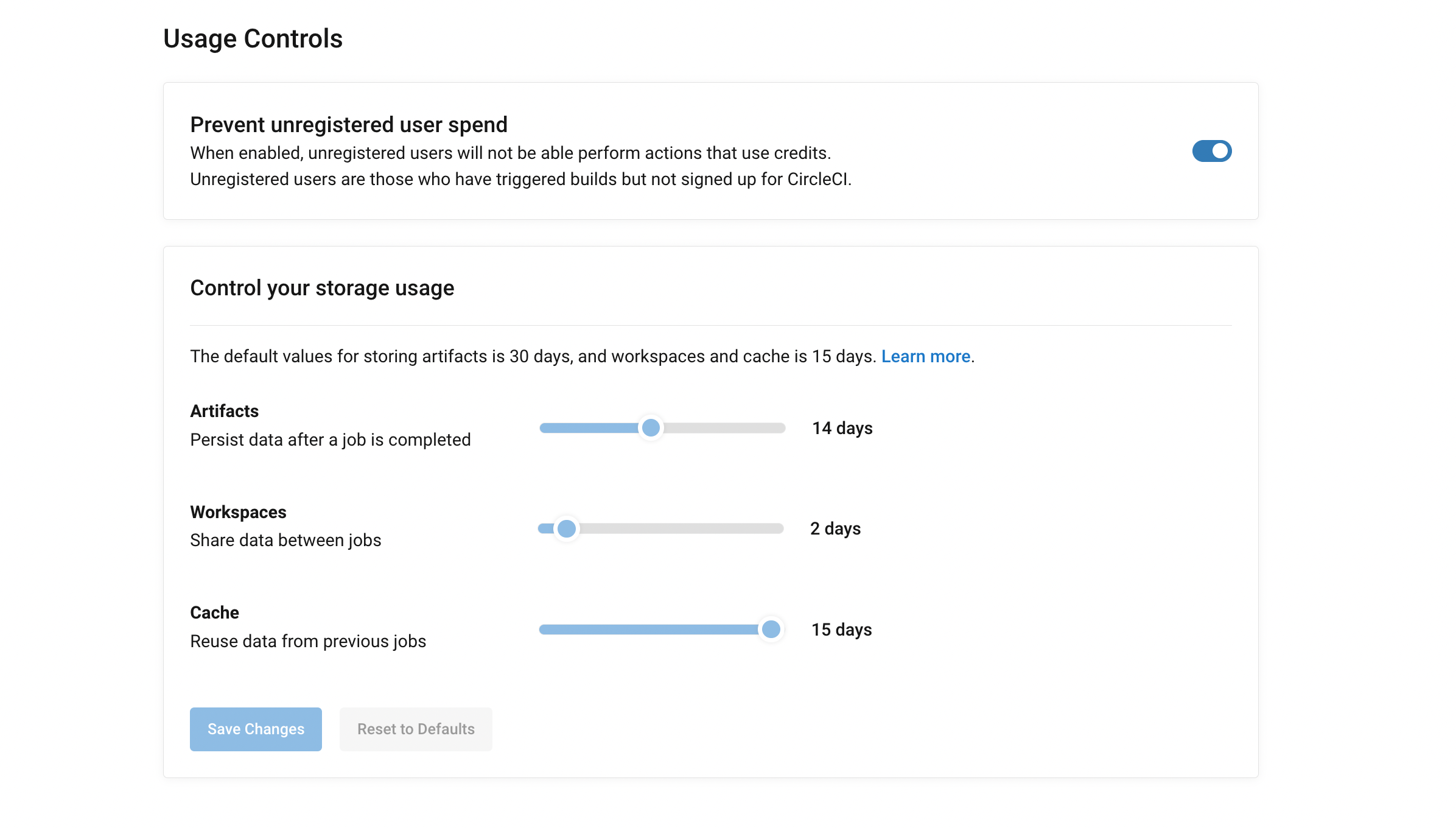
🔄 Auto-rerun failed test cases
Once the optimizations were done, flaky test cases became the bane of our existence. Since this would be counter-productive to the main objective of lowering the load on developers. We utilized a library called pytest-rerunfailures, which, as the name suggests, re-runs failed test cases. But the problem is that this is not a library required for production and is not maintained/secured to be installed in production. Hence it was added in a test.txt file in the requirements directory, and since we utilize
for file in requirements/*.txt; do pip install -r "$file"; doneit will be installed during test runs and not in any other server.- run: # we split the test cases using glob and generate the report at the end of the test run name: Run tests and create report command: | pytest ${TESTFILES} -n 4 --reuse-db --junitxml=test-results/reports/junit.xml --reruns 3 -x--reruns 3reruns the failed test case up to 3 times, and if one of them passes, it goes ahead with the rest.-xwill exit immediately after a test case fails, even after 3 rerunsCost vs Impact
- No cost add-on for this change, but it caused the flaky test cases to be reduced significantly from 2-3 flaky test cases failures per job run to 1 flaky failure in every 10-15 test runs.
Caveats
Make sure to include
-xin the command, if your pipeline is configured to fail even if one test case fails since that will save some credits.You could also set it to only rerun test cases with a specific type of failure like this:
--only-rerun AssertionErrorthis will only rerun test cases that have failed due to AssertionError.
We're hiring!
If solving challenging problems at scale in a fully-remote team interests you, head to our careers page and apply for the position of your liking!